
Last night I read the post and comments over at
Pandas Thumb about the latest
kerfluff over a simple search algorithm given by Richard Dawkins in his 1986 book
The Blind Watchmaker. "Oh That's Easy!" I thought, "It's so simple I could even code that in a spreadsheet."
This morning I did just that, and you can
download the spreadsheet and try it yourself.
This being a spreadsheet a manual step is required, and some instructions are needed in any case. Below is a screen-shot of the spreadsheet:
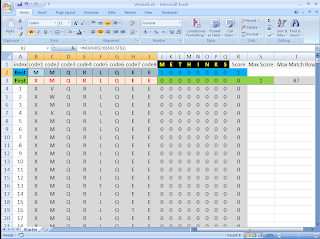
Columns
B:I represent 8 letter codes that can be selected. Cells
B3:I3 are the "parent" string, randomly generated letter
A-Z, and below that are 500 "children" of the parent. Each letter has a 5% chance of being randomly replaced in each child string.
(I'll come back to cells B2:I2).
Cells
J1:Q1 (black block with yellow text) give a target string "METHINKS". Below this is a grade for the codes of the parent and each child string. Each of the 8 codes receive a 1 (one) if it matches the target, and a 0 (zero) if it does not. Theses grades are totaled to determine the "Score" for each. The maximum score is given, along with a row number of the maximum (used internally, it does not match actual row numbers).
For this first "generation" of children, the maximum number of matches to the target string is 1, and the codes corresponding to the first occurrence of this maximum, or the "best" scoring match, are displayed in cells
B2:I2. The maximum Score is 1, and you can see that cell
C2 contains the single correct match.
Now comes the manual step, because I don't want to get into macros for automatic updating:

1) Select cells
B2:I2 and Copy.
2) Select cell
B3.
3) Choose: Paste --> Paste Values. This should replace the contents of cells
B3:I3 with what you copied from
B2:I2.
The spreadsheet will automatically update (so fast you will probably miss it). Congratulations, you have just created generation #2. As you can see in my example above, the "best" string now has two correct matches. This manual step carries forward any improvement in matching the target string from one generation to the next.
Now repeat the manual step again for generation #3:

My example now has three correct matches. This would not have to be the case - it is possible to get a new generation where the score does not increase. It is even possible that the score among the children could actually go down; there is
no latching. A score going down would be rare as I have defined this. I could increase the probability of this happening by increasing the mutation rate. Also, as I have defined this, the Score for the parent is included among the children's Scores, so the maximum Score cannot actually decrease from one generation to the next. That would be easy enough to change.
Generation #4:

Generation #5:

Generation #6:
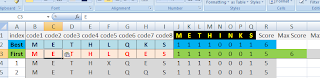
Generation #7:
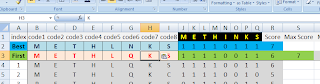
Generation #9:
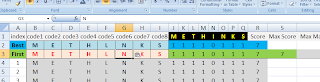
That's right, #9, not #8. My #8 did not improve in Score over #7, and so it stayed the same. In this case you can skip the
cut-and-paste step and press the
F9 key to recalculate the next generation instead.
Generation #10:

We have arrived! The Best string is now "METHINKS" which matches the target. No embedded information, just a crude sort of random hill-climbing algorithm.
Still this isn't a very good representation of evolution. An improvement representation would be to allow all the highest scoring children to reproduce, not just the first one as in my simple demonstration. I think perhaps Dawkins' original algorithm allowed for this.
I wonder what the folks over at
Uncommon Decent will have to say about this?

Here is a link to some other
WEASEL algorithms, originally organized by
Ian Musgrave. I haven't actually looked at these, but I'll wager they are all better than mine.












 [Image LaughingSquid]
[Image LaughingSquid]
 Gregory Benford: "We think of black holes as God's dumpster, but they really are actors on the galactic stage."
Gregory Benford: "We think of black holes as God's dumpster, but they really are actors on the galactic stage." More pretty pictures.
More pretty pictures.


 It's nice to have visitors, but SPAM, not so much. I want to allow as much freedom for comments as I can, but there have to be some sort of limits too. Therefore, some rules:
It's nice to have visitors, but SPAM, not so much. I want to allow as much freedom for comments as I can, but there have to be some sort of limits too. Therefore, some rules:
